"Not all who wonder are lost"
Not so recently I've been looking at this code that de-serializes messages through a profiler and a hotspot came up around the decoding/encoding of UTF8 strings. Certainly, I thought to myself, this is all sorted by some clever people somewhere, had a look around and found lots of answers but not much to keep me happy. What's the big deal you wonder:- UTF8 is a clever little encoding, read up on what it is on Wikipedia. Not as simple as those lovely ASCII strings and thus far more expensive to encode/decode. The problem is that Strings are backed by char arrays, which in turn can only be converted back and forth to bytes using encodings. A UTF8 char can be encoded to 1-4 bytes. The Strings also do not have a length in bytes, and are often serialized without that handy piece of information being available, so it's a case of finding how many bytes you need as you go along (see the end result implementation for a step by step).
- Java Strings are immutable and defensive, if you give them chars they copy it, if you ask for the chars contained they get copied too.
- There are many ways to skin the encoding/decoding cat in Java that are considered standard. In particular there are variations around the use of Strings, Charsets, arrays and Char/Byte buffers (more on that to come).
- Most of the claims/samples I could find were not backed by a set of repeatable experiments, so I struggled to see how the authors arrived at the conclusions they did.
"Looking? Found someone you have!"
After much looking around I've stumbled upon this wonderful dude at MIT Evan Jones and his excellent set of experiments on this topic Java String Encoding and his further post on the implementation behind the scenes. Code is now on GitHub(you'll find it on his blog in the form of a zip, but I wanted to fork/branch from it): https://github.com/nitsanw/javanetperf and a branch with my code changes is under https://github.com/nitsanw/javanetperf/tree/psylobsaw
Having downloaded this exemplary bit of exploratory code I had a read and ran it (requires python). When I run the benchmarks included in the zip file on my laptop I get the following results(unit of measurement has been changed to millis, upped the test iterations to 1000 etc. The implementation is the same, I was mainly trying to get stable results):
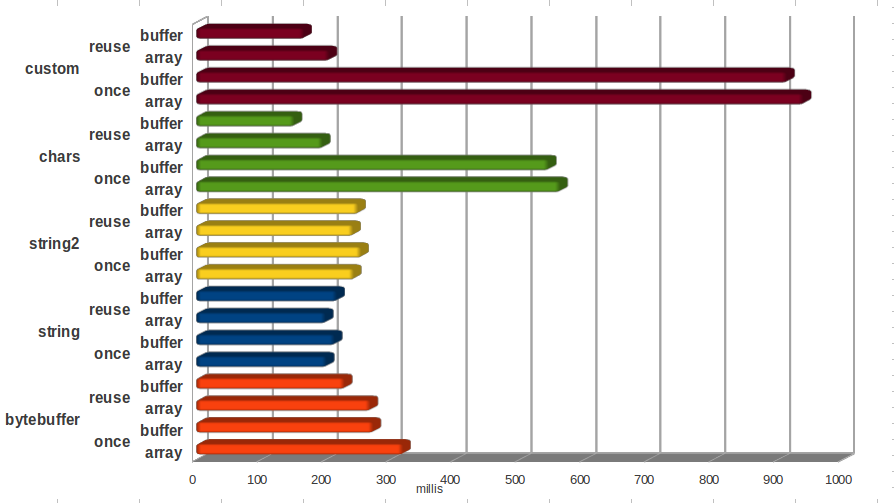
* The above was run using JDK 1.6.37 on Ubuntu 12.04(64bit) on with an i5-2540M CPU @ 2.60GHz × 4.
I find the names a bit confusing, but Mr. Jones must have had his reasons. In any case here's what they mean:
I find the names a bit confusing, but Mr. Jones must have had his reasons. In any case here's what they mean:
- bytebuffer - uses a CharBuffer.wrap(String input) as the input source to an encoder.
- string - uses String.getBytes("UTF-8")
- chars - copies the string chars out by using String.getChars, the chars are the backing array for a CharBuffer then used as the input source to an encoder.
- custom - steals the char array out of String by using reflection and then wrapping the array with a CharBuffer.
- once/reuse - refers to the encoder object and it's bits, weather a new once was created per String or the same reused.
- array/buffer - refers to the destination of the encoding a byte array or a ByteBuffer.
- There are indeed many flavours for this trick, and they vary significantly in performance.
- The straight forward, simplest way i.e. using String.getBytes() is actually not bad when compared to some of the other variations. This is quite comforting on the one hand, on the other hand it highlights the importance of measuring performance 'improvements'.
- The best implementation requires caching and reusing all the working elements for the task, something which happens under the hood in String for you. String also caches them in thread local variables, so in fact gives you thread safety on top of what other encoding implementations offer.
- Stealing the char array using reflection is more expensive then copying them out. Teaching us that crime does not pay in that particular case.
"Focus!"
The use case I was optimizing for was fairly limited, I needed to write a String into a ByteBuffer. I knew a better way to steal the char array, as discussed in a previous post, using Unsafe(called that one unsafe). Also, if I was willing to tempt fate by re-writing final fields I could avoid wrapping the char array with a new CharBuffer(called that one unsafe2). I also realized that calling encoder.flush() was redundant for UTF-8 so trimmed that away(for both unsafe implementations, also did the same for chars and renamed chars2). Re-ran and got the following results, the chart focuses on the use case and adds relevant experiments:
We got a nice 10% improvement there for stealing the char[] and another 5% for re-writing a final field. Not to be sneezed at, but not that ground breaking either. It's worth noting that this is 10-15% saved purely by skipping a memory copy and the CharBuffer wrap, which tells us something about the cost of memory allocations when compared to raw computation cycles.
To further improve on the above I had to dig deeper into the encoder (which is where unsafe3 at above comes into play) implementation which uncovered good news and bad news.
"The road divides"
The bad news were an unpleasant little kink in the works. As it turns out string encoding can go down 2 different paths, one implementation is array based for heap ByteBuffers(on heap, backed by arrays), the other works through the ByteBuffer methods(so each get/set does explicit boundary checks) and will be the chosen path if one of the buffers is direct (off heap buffers). In my case the CharBuffer is guaranteed to be heap, but it would be quite desirable for the ByteBuffer to be direct. The difference in performance when using a direct ByteBuffer is quite remarkable, and in fact the results suggest you are better off using string and copying the bytes into the direct buffer. But wait, there's more."And then there were three"
The good news were that the topic of String encoding has not been neglected and that it is in fact improving from JDK version to JDK version. I re-run the test for JDK5, 6 and 7 with heap and direct buffers. I won't bore you with the losers of this race, so going forward we will look only at string, chars2, and the mystery unsafe3. The results for heap buffers: |
| Heap buffer encoding results |
The results for direct buffers(note the millis axis scale difference):
What can we learn from the above?
And there you have it, a way to encode strings into byte buffers that is at least 30% faster then the JDK provided ones(for now) which gives you consistent performance across JDK versions and for heap and direct buffers :)
References:
 |
| Direct buffer encoding results |
- JDK string encoding performance has improved dramatically for the getBytes() users. So much in fact that it renders previous best practice less relevant. The main benefit of going down the Charset encode route is the memory churn reduction.
- The improvement for the unsafe implementation suggests there were quite a few underlying improvements in the JIT compiler for in-lining intrinsics.
- Speed has increased across the board for all implementations, joy for all.
- If you are providing a framework or a library you expect people to use with different JDKs and you need to provide comparable performance you need to be aware of underlying implementation changes and their implications. It might make sense to back port bit of the new JDK and add them to your jar as a means of bringing the same goods to users of old JDKs. This sort of policy is fairly common with regards to the concurrent collections and utilities.
"Use the Source Luke"
At some point I accepted that to go faster I will have to roll up my sleeves and write an encoder myself(have a look at the code here). I took inspiration from a Mark Twain quote: "The kernel, the soul — let us go further and say the substance, the bulk, the actual and valuable material of all human utterances — is plagiarism.". No shame in stealing from your betters, so I looked at how I could specialize the JDK code to my own use case:- I was looking at encoding short strings, and knew the buffers had to be larger then the strings, or else bad things happen. As such I could live with changing the interface of the encoding such that when it fails to fit the string in the buffer it returns overflow and you are at the same position you started. This means encoding is a one shot operation, no more encoding loop picking the task up where they left it.
- I used Unsafe to pick the address out of the byte buffer object and then use it to directly put bytes into memory. In this case I had to keep the boundary checks in, but it still out performed the heap one in JDK7, so maybe the boundary checks are not such a hindrance. I ran out of time with this, so feel free to experiment and let me know.
- I tweaked the use of types and the constants and so on until it went this fast. It's fiddly work and you must do it with an experiment to back up your theory. At least from my experience a gut feeling is really not sufficient when tuning your code for performance. I would encourage anyone with interest to have a go at changing it back and forth to the JDKs implementation and figuring out the cost benefit of each difference. If you can further tune it please let me know.
- Although not explicitly measured throughout this experiment there is a benefit in using the unsafe3 method(or something similar) in reducing the memory churn involved in the implementation. The encoder is very light weight and ignoring it's own memory cost involves no further memory allocation or copying in the encoding process. This is certainly not the case for either the chars2 solution or the string one and the overhead is proportional to the encoded string length.
- This same approach can be used to create an encoder that would conform to the JDK interface. I'm not sure what the end result would perform like, but if you need to conform to the JDK interface there's still a win to be had here.
- The direct buffer results suggest it might be possible to further improve the heap buffer result by using unsafe to put the byte in rather than array access. If that is the case then it's an interesting result of and by itself. Will be returning to that one in future.
And there you have it, a way to encode strings into byte buffers that is at least 30% faster then the JDK provided ones(for now) which gives you consistent performance across JDK versions and for heap and direct buffers :)
References:
- Java String Encoding - Evan Jones blog entry on the topic.
- https://github.com/nitsanw/javanetperf/tree/psylobsaw - The original experiments along with my changes and new encoder.
- JDK7 UTF-8 Charset source with Encoder/Decoder
- JDK6 UTF-8 Charset source with Encoder/Decoder
Would it make a difference if you used bit "magic" to store them using longs?
ReplyDeletemmmm... I'm certain that reading/writing longs instead of bytes is faster. Adding a long as an 8 byte buffer to be used for encoding may improve overall performance, especially for longer Strings. For HeapByteBuffer you need to be aware of the fact that putLong is in fact 8 byte writes. If you go down the Unsafe path for writing the long you need to be aware of the expect byte ordering.
DeleteOnly one way to find out though, and I've got other projects on the go at the moment. I suggest you hack on the code and benchmark before/after. I recommend use use the JMH (see the Getting Started with JMH post) variant of the benchmark as it's much shorter and the framework is more powerful.
If you find the time to explore this optimisation please share.
Hmmm, seeing those getFieldOffsets makes me weary. See this discussion about why it might be a problem in the future: https://groups.google.com/forum/#!topic/mechanical-sympathy/X-GtLuG0ETo
ReplyDeleteAlternatively, I would be interested what the performance of using reflection (+setAccessible) is. I've read that recent JVM versions are capable of generating efficient code for reflection access too and I would prefer something which is 5-10% slower (but still faster than the "official" way) and has a guarantee of working vs. something that is faster but possibly can cause my JVM to segfault (I already can segfault the JVM with pure Java code, don't need to add Unsafe to the mix :-))
There's a variation using reflection in there somewhere, but it didn't perform well enough to be worth a mention. If you want to be safe I suggest you stick to the CharBuffer/ByteBuffer approach, and watch out for DirectByteBuffers.
DeleteYou are right to be nervous, one thing I came across writing this post is the change to the String class making the code written for JDK6 which relied on offsets break for JDK7. This is not really recommended practice, more of a study of the possibilities.
Still in an environment where speed is of the outmost priority, and where you can specify the versions you deal with, this approach can work. And it is significantly faster. To summarise, Unsafe is risky business, you may poke your eye out :-) but if you feel confident and can afford the risk, go for your life. On that same discussion, or a similar one I had suggested code using Unsafe should void your JVM provider liability/support. The code is presented for your consideration.
Thanks for reading :-).
Did you try using String.charAt(x)?
ReplyDeletemmm.... no. This is 2 years almost since the post was written. I may have tried it at the time... not sure.
DeleteThe code is available on github for all to play with, I suggest you have a play and share your results. I recommend you use the JMH variant of the benchmark that is easier to play with and offers better measurement: https://github.com/nitsanw/jmh-samples