To this:
This change yields a great improvement in throughput which I explained to be down to the reduction in coherency traffic between the cores. This is:
- Not what I stated previously here.
- A very brief and unsatisfying explanation.
Penance
In my original step by step post I explained the benefit of the above optimization is the replacement of a volatile read with a plain read. Martin was kind enough to gently correct me in the comments:"The "volatile read" is not so much the issue. The real issues come from the read of the head or tail from the opposite end will pretty much always result in a cache miss. This is because the other side is constantly changing it."and I argued back, stating the JIT compiler can hoist the field into a register and wistfully wishing I could come up with an experiment to prove one way or the other. I was mostly wrong and Martin was totally right.
I say mostly and not entirely because eliminating volatile reads is not a bad optimization and is responsible for part of the perf improvement. But it is not the lion share. To prove this point I have hacked the original version to introduce volatile reads (but still plain writes) from the headCache/tailCache fields. I won't bore you with the code, it's using the field offset and Unsafe.getLongVolatile to do it.
I ran the test cross core for 30 times and averaged the summary results. Running on new hardware (so no reference point to prev. quoted results) i7-4700MQ/Ubuntu 13.04/JDK7u25. Here are the results, comparing Original21 (head/tail padded, no cache fields), Original3 (head/tail padded, head/tailCache padded) and VolatileRead (same as Original3, but with volatile read of cache fields):
Original21: 65M ops/sec
Original3: 215M ops/sec
VolatileRead: 198M ops/sec
As we can see, there is no massive difference between Original3 and VolatileRead (especially when considering the difference from Original21), leading me to accept I need to buy Martin a beer, and apologize to any reader of this blog who got the wrong idea reading my post.
Exercise to the reader: I was going to run the above with perf to quantify the impact on cache-misses, but as perf doesn't support this functionality on Haswell I had to let it go. If someone cares to go through the exercise and post a comment it would be most welcome.
What mean cache coherency?
Moving right along, now that we accept the volatile read reduction is not the significant optimization here, let us dig deeper into this cache coherency traffic business. I'll avoid repeating what is well covered elsewhere (like cache-coherence, or MESIF on wikipedia, or this paper, some excellent examples here, and an animation for windows users only here) and summarize:
 |
| MESI State Diagram |
- Modern CPUs employ a set of caches to improve memory access latency.
- To present us with a consistent view of the world when concurrent access to memory happens the caches must communicate to give us a coherent state.
- There are variations on the protocol used. MESI is the basic one. Recent intels use MESIF. In the examples below I use MESI as the added state in MESIF adds nothing to the use case.
- The guarantee they go for is basic:
- One change at a time (to a cache line): A line is never in M state in more than one place.
- Let me know if I need a new copy: If I have a copy and someone else changed it I need to get me a new copy. (My copy will move from Shared to Invalid)
False Sharing (once more)
False sharing is a manifestation of this issue where 2 threads are competing to write to the same cache line which is constantly Invalid in their own cache.Here's a blow by blow account of false sharing in terms of cache coherency traffic:

- Thread1 and Thread2 both have the false Shared cache line in their cache
- Thread1 modifies HEAD (state goes from S to E), Thread2's copy is now Invalid
- Thread2 wants to modify TAIL but his cache line is now in state I, so experiences a write miss:
- Issue a Read With Intent To Modify (RWITM)
- RWITM intercepted by Thread1
- Thread1 Invalidates own copy
- Thread1 writes line to memory
- Thread2 re-issues RWITM which results in read from memory (or next layer cache)
- Thread1 wants to write to HEAD :( same song and dance again, the above gets in it's way etc.
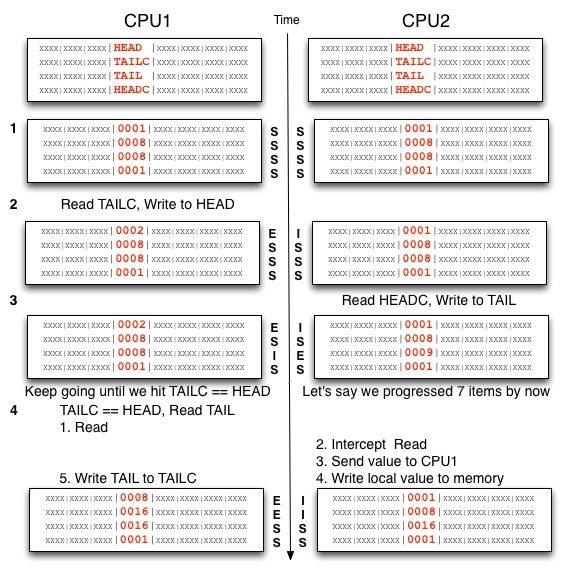
The diagram to the right is mine, note the numbers on the left track the explanation and the idea was to show the cache lines as they mutate on a timeline. Hope it helps :-).
Reducing Read Misses
So False Sharing is really bad, but this is not about False Sharing (for a change). The principal is similar though. With False Sharing we get Write/Read misses, the above manoeuvre is about eliminating Read misses. This is what happens without the HEADC/TAILC fields (C for cache):- Thread1 and Thread2 both have the HEAD/TAIL cache lines in Shared state in their cache
- Thread1 modifies HEAD (state goes from S to E), Thread2's copy is now Invalid
- Thread2 wants to read HEAD to check if the queue wrapped, experiences a Read Miss:
- Thread2 issues a request for the HEAD cache line
- Read is picked up by Thread1
- Thread1 delivers the HEAD cache line to Thread2, the request to memory is dropped
- The cache line is written out to main memory and now Thread1/2 have the line in Shared state

- Thread1 and Thread2 both have the HEAD/TAIL/HEADC/TAILC cache lines in Shared state in their cache (the TAILC is only in Thread1, HEADC is only in Thread2, but for symmetry they are included).
- Thread1 reads TAILC and modifies HEAD (state goes from S to E), Thread2's copy is now Invalid.
- Thread2 reads from HEADC which is not changed. If TAIL is less than HEADC we can make progress (offer elements) with no further delay. This continues until TAIL is equal to HEADC. As long as this is the case HEAD is not read, leaving it in state M in Thread1's cache. Similarly TAIL is kept in state M and Thread2 can make progress. This is when we get the great performance boost as the threads stay out of each others way.
- Thread1 now needs to read TAIL to check if the queue wrapped, experiences a Read Miss:
- Thread1 issues a request for the TAIL cache line
- Request is picked up by Thread2
- Thread2 delivers the TAIL cache line to Thread1, the request to memory is dropped
- The cache line is written out to main memory and now Thread1/2 have the line in Shared state
- TAIL is written to TAILC (TAILC line is now E)
Summary
In an ideal application (from a cache coherency performance POV) threads never/rarely hit a read or write miss. This translates to having single writers to any piece of data, and minimizing reads to any external data which may be rapidly changing. When we are able to achieve this state we are truly bound by our CPU (rather than memory access).
The takeaway here is: Fast moving data should be in M state as much as possible. A read/write miss by any other thread competing for that line will lead to reverting to S/I which can have significant performance implications. The above example demonstrates how this can achieved by caching stale but usable copies locally to another thread.
There are architectural performance events which let you record read/write rates on a per cacheline-state basis. So you can get events for things in each of the MESI states. You could use those architectural events in order to validate the increase in number of reads/writes in M.
ReplyDeleteI don't know if perf supports those counters, but even if it doesn't, it should simply be a matter of using a different magic number when it programs the performance event counters.
I simply ran out of time... By all means please post the results to win a pint of beer of your choice! :)
DeleteI'll look into it when I get back from holiday. Thanks.
Wasn't in town to see your talk at FB. But discovered your blog from the meeting invite. This is excellent.
ReplyDeleteSorry to have missed you, and very glad you like it :).
DeleteYou should be able to find further links on the summary slide of the talk.
Is there a way to view false sharing using a profiler ? I have seen a PPT that shows it using Oracle Studio Analyzer. I have Windows and Mac.
ReplyDeleteMohan
Diagnosing false sharing in a micro-benchmark is quite straight forward by using 'perf stat' or another tool which expose hardware counters and will show you high numbers of cache misses. There is a nice Intel tool: http://software.intel.com/en-us/articles/intel-performance-counter-monitor which is free and works for linux/windows/mac.
DeleteWhile the cache misses are indicative in a benchmark they are hard to attribute to any particular piece of code in a large system using process level performance counters. To achieve that you should use a profiler which can relate the performance counters to the offending line of code/data structure. Oracle Performance Analyzer offers that functionality on Solaris. It is also supported on Linux but I'm not sure it's fully functional, in particular the performance counters analysis is more precise on Solaris according the C. Hunt Java Performance (good reference book to have BTW). On Windows/Mac you can use Intel VTune (assuming you have an Intel CPU) which is a commercial tool.
Interesting tool. I was going to use @Contended and look at the metrics.
DeleteDon't know if with Java how it could work..but I've found this: https://joemario.github.io/blog/2016/09/01/c2c-blog/
ReplyDelete